SSD作为one-stage目标检测算法中比较经典且具有代表性的一种方法。其精度可以与Faster R-CNN相匹敌,而速度达到了惊人的59FPS,速度上完爆 Faster R-CNN。相比于Faster R-CNN,其速度快的根本原因在于移除了region proposals的步骤以及后续的像素采样或特征采样步骤。论文连接:SSD: Single Shot MultiBox Detector,作者开源的代码连接:code。由于作者开源代码使用caffe实现,这里以pytorch源码的方式实现。作者在论文中实现了两种不同输入大小的SSD模型:SSD300(输入图像大小统一为300x300)以及SSD512(输入图像大小统一为512x512).这里主要针对SSD300,下面主要分四个部分介绍SSD300以及代码具体实现。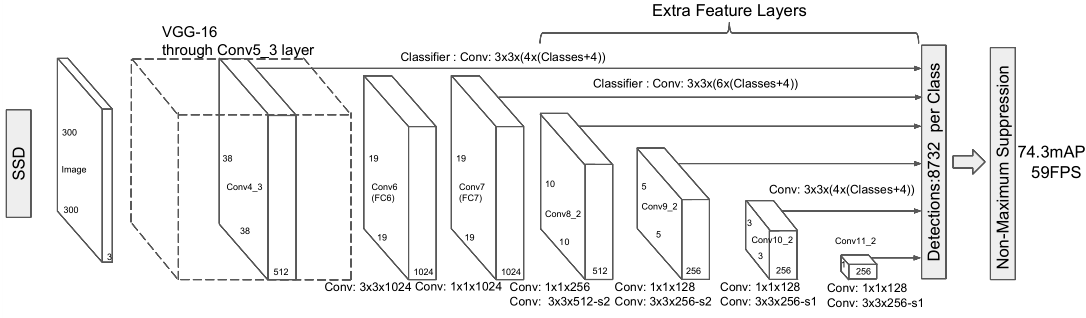
Base Convolutions
如上图所示,在SSD算法中基础网络采用的是VGG-16结构作为其基础网络。与VGG-16不同的是,把fc6和fc7替换成了卷积层。替换后的backbone结构如下图所示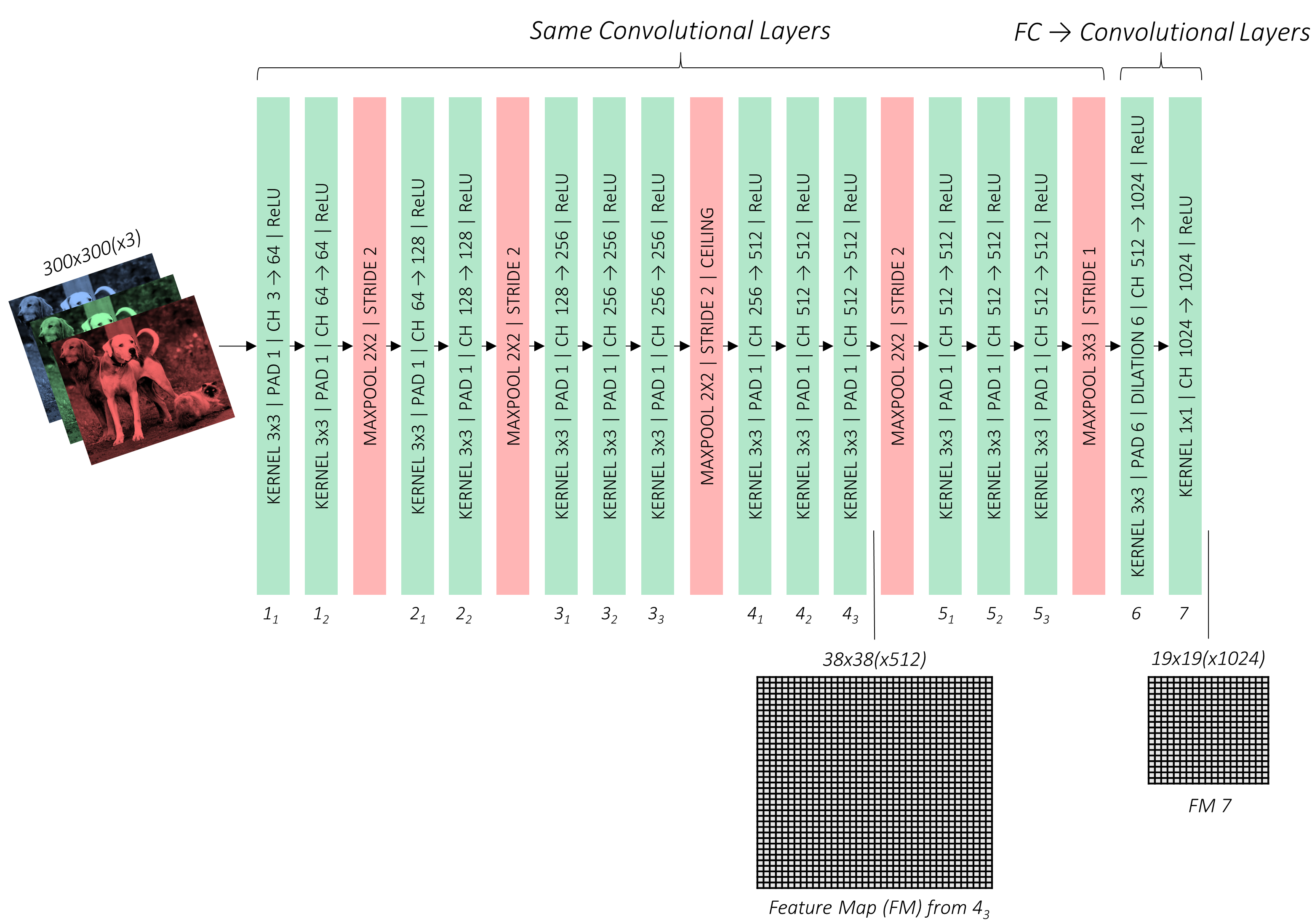
对应代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78class VGGBase(nn.Module):
"""
VGG base convolutions to produce lower-level feature maps.
"""
def __init__(self):
super(VGGBase, self).__init__()
# Standard convolutional layers in VGG16
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, padding=1) # stride = 1, by default
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True) # ceiling (not floor) here for even dims
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # retains size because stride is 1 (and padding)
# Replacements for FC6 and FC7 in VGG16
self.conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6) # atrous convolution
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
# Load pretrained layers
self.load_pretrained_layers()
def forward(self, image):
"""
Forward propagation.
:param image: images, a tensor of dimensions (N, 3, 300, 300)
:return: lower-level feature maps conv4_3 and conv7
"""
out = F.relu(self.conv1_1(image)) # (N, 64, 300, 300)
out = F.relu(self.conv1_2(out)) # (N, 64, 300, 300)
out = self.pool1(out) # (N, 64, 150, 150)
out = F.relu(self.conv2_1(out)) # (N, 128, 150, 150)
out = F.relu(self.conv2_2(out)) # (N, 128, 150, 150)
out = self.pool2(out) # (N, 128, 75, 75)
out = F.relu(self.conv3_1(out)) # (N, 256, 75, 75)
out = F.relu(self.conv3_2(out)) # (N, 256, 75, 75)
out = F.relu(self.conv3_3(out)) # (N, 256, 75, 75)
out = self.pool3(out) # (N, 256, 38, 38), it would have been 37 if not for ceil_mode = True
out = F.relu(self.conv4_1(out)) # (N, 512, 38, 38)
out = F.relu(self.conv4_2(out)) # (N, 512, 38, 38)
out = F.relu(self.conv4_3(out)) # (N, 512, 38, 38)
conv4_3_feats = out # (N, 512, 38, 38)
out = self.pool4(out) # (N, 512, 19, 19)
out = F.relu(self.conv5_1(out)) # (N, 512, 19, 19)
out = F.relu(self.conv5_2(out)) # (N, 512, 19, 19)
out = F.relu(self.conv5_3(out)) # (N, 512, 19, 19)
out = self.pool5(out) # (N, 512, 19, 19), pool5 does not reduce dimensions
out = F.relu(self.conv6(out)) # (N, 1024, 19, 19)
conv7_feats = F.relu(self.conv7(out)) # (N, 1024, 19, 19)
# Lower-level feature maps
return conv4_3_feats, conv7_feats
值得注意的是:
- pool3采用的是向上取整操作,ceil(75/2)=38;
- 将原始pool5(2x2,stride 2)修改为pool5(3x3,stride 1),这样改的结果是,pool5操作不改变特征图大小;
- 将VGG16中的fc6,fc7替换成卷积层conv6,和conv7,此外,conv6使用了atrous卷积;
- 去掉了所有的dropout层和fc8层;
- VGGBase输出的是conv4_3和conv_7的feature map;
Atrous/dilated 卷积使用说明:
通常卷积过程中为了使特征图尺寸特征图尺寸保持不变,通过会在边缘打padding,但人为加入的padding值会引入噪声,因此,使用atrous卷积能够在保持感受野不变的条件下,减少padding噪声。
Auxiliary Convolutions
为了能够充分利用不同大小的feature map用于目标检测,作者在Base Convolutions的基础上,在conv_7后面又堆叠了8层卷积用于生成不同大小的特征图。如下图所示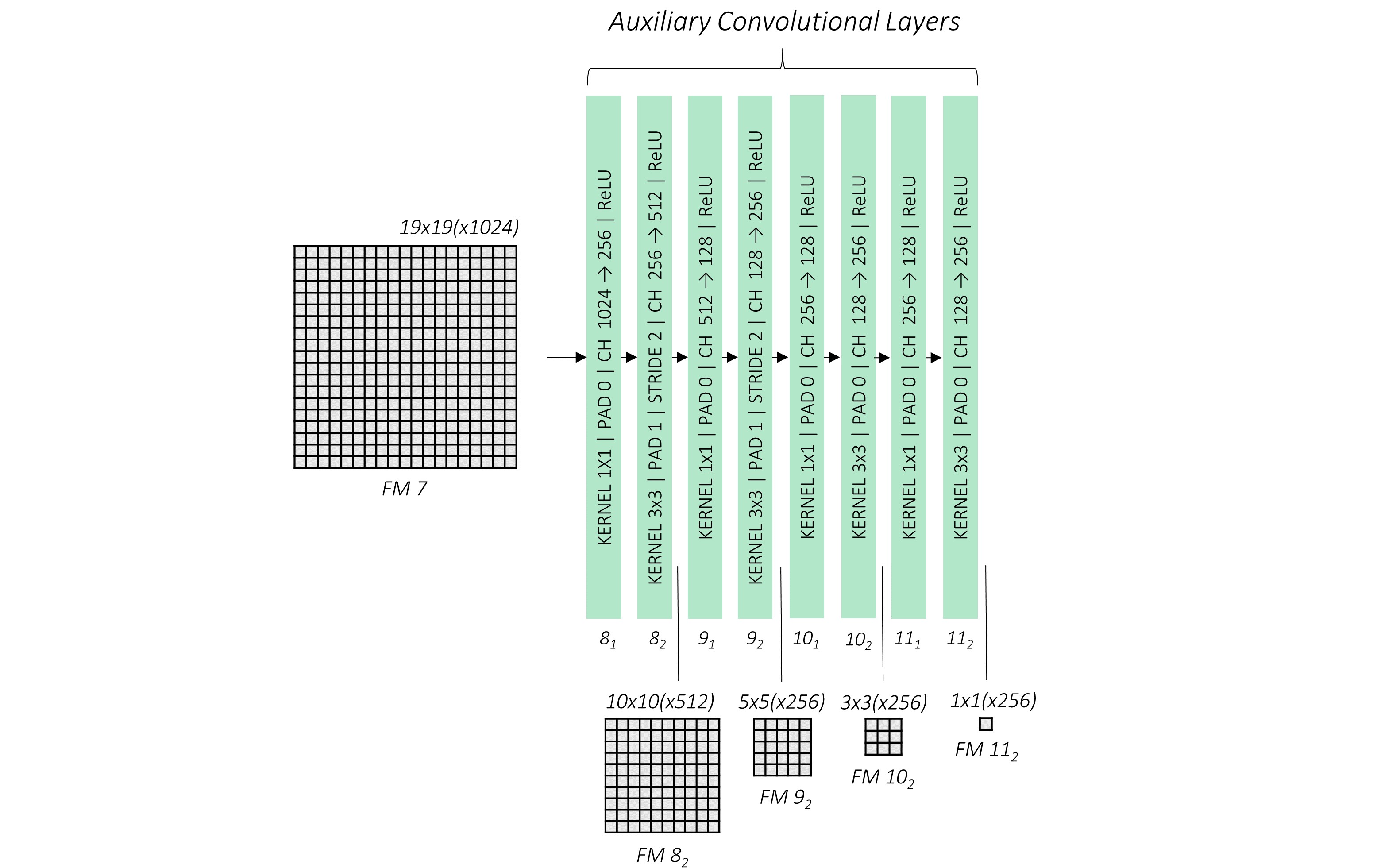
对应代码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57class AuxiliaryConvolutions(nn.Module):
"""
Additional convolutions to produce higher-level feature maps.
"""
def __init__(self):
super(AuxiliaryConvolutions, self).__init__()
# Auxiliary/additional convolutions on top of the VGG base
self.conv8_1 = nn.Conv2d(1024, 256, kernel_size=1, padding=0) # stride = 1, by default
self.conv8_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1) # dim. reduction because stride > 1
self.conv9_1 = nn.Conv2d(512, 128, kernel_size=1, padding=0)
self.conv9_2 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1) # dim. reduction because stride > 1
self.conv10_1 = nn.Conv2d(256, 128, kernel_size=1, padding=0)
self.conv10_2 = nn.Conv2d(128, 256, kernel_size=3, padding=0) # dim. reduction because padding = 0
self.conv11_1 = nn.Conv2d(256, 128, kernel_size=1, padding=0)
self.conv11_2 = nn.Conv2d(128, 256, kernel_size=3, padding=0) # dim. reduction because padding = 0
# Initialize convolutions' parameters
self.init_conv2d()
def init_conv2d(self):
"""
Initialize convolution parameters.
"""
for c in self.children():
if isinstance(c, nn.Conv2d):
nn.init.xavier_uniform_(c.weight)
nn.init.constant_(c.bias, 0.)
def forward(self, conv7_feats):
"""
Forward propagation.
:param conv7_feats: lower-level conv7 feature map, a tensor of dimensions (N, 1024, 19, 19)
:return: higher-level feature maps conv8_2, conv9_2, conv10_2, and conv11_2
"""
out = F.relu(self.conv8_1(conv7_feats)) # (N, 256, 19, 19)
out = F.relu(self.conv8_2(out)) # (N, 512, 10, 10)
conv8_2_feats = out # (N, 512, 10, 10)
out = F.relu(self.conv9_1(out)) # (N, 128, 10, 10)
out = F.relu(self.conv9_2(out)) # (N, 256, 5, 5)
conv9_2_feats = out # (N, 256, 5, 5)
out = F.relu(self.conv10_1(out)) # (N, 128, 5, 5)
out = F.relu(self.conv10_2(out)) # (N, 256, 3, 3)
conv10_2_feats = out # (N, 256, 3, 3)
out = F.relu(self.conv11_1(out)) # (N, 128, 3, 3)
conv11_2_feats = F.relu(self.conv11_2(out)) # (N, 256, 1, 1)
# Higher-level feature maps
return conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats
如SSD论文在section 3.1提到的一样,新添加的卷积层的初始化采用的xavier初始化方法。AuxiliaryConvolutions输出的是不同大小的feature map:conv8_2, conv9_2, conv10_2, and conv11_2。对于SSD512,作者在conv11_2后面来额外添加了两层conv12。
SSD算法中使用到了conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,conv11_2这些大小不同的feature maps,其目的是为了能够准确的检测到不同尺度的物体,因为在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
Priors
在继续进行预测卷积之前,我们必须首先了解我们预测的是什么。当然,这是物体和它们的位置,但是以什么形式?在这里,我们必须了解priors以及它们在SSD中所起的关键作用。priors和anchor的概念类似,也是预先在feature map上定义一些不同大小形状的box,然后再这个基础上进行回归预测分类目标。如下图所示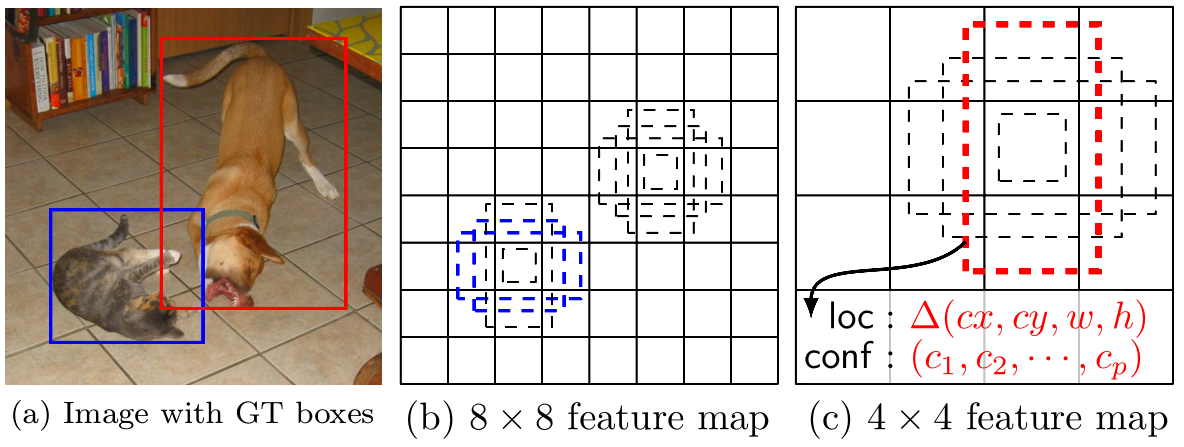
如上图所示,在特征图的每个位置预测K个box,对于每一个box,预测C个类别得分,以及相对于prior box的4个偏移量值,这样总共需要(C+4) K个预测器,则在mn的特征图上面将会产生(C+4) K m * n个预测值。在SSD300中,分别在6个不同尺度的feature map上生成prior box。对应prior box如下:
| Feature Map From | Feature Map Dimensions | Prior Scale | Aspect Ratios | Number of Priors per Position | Total Number of Priors on this Feature Map |
|---|---|---|---|---|---|
conv4_3 |
38, 38 | 0.1 | 1:1, 2:1, 1:2 + an extra prior | 4 | 38x38x4=5776 |
conv7 |
19, 19 | 0.2 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 19x19x6=2166 |
conv8_2 |
10, 10 | 0.375 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 10x10x6=600 |
conv9_2 |
5, 5 | 0.55 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 5x5x6=150 |
conv10_2 |
3, 3 | 0.725 | 1:1, 2:1, 1:2 + an extra prior | 4 | 3x3x4=36 |
conv11_2 |
1, 1 | 0.9 | 1:1, 2:1, 1:2 + an extra prior | 4 | 1x1x4=4 |
| Grand Total | – | – | – | – | 8732 priors |
Prior Scale计算公式如下: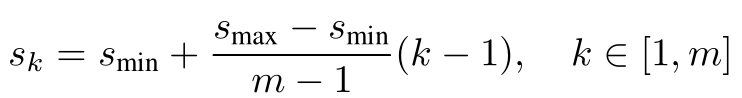
其中,$s{min}=0.2,s{max}=0.9$,conv4_3设置为0.1。
值得注意的是,对于aspect ratio为1的时候,作者额外添加了一个extra prior,对应的additional_scale:
因此在SSD300中总共有9732个prior boxes !
对于每一个priorbox,对应宽度w和高度h的计算如下: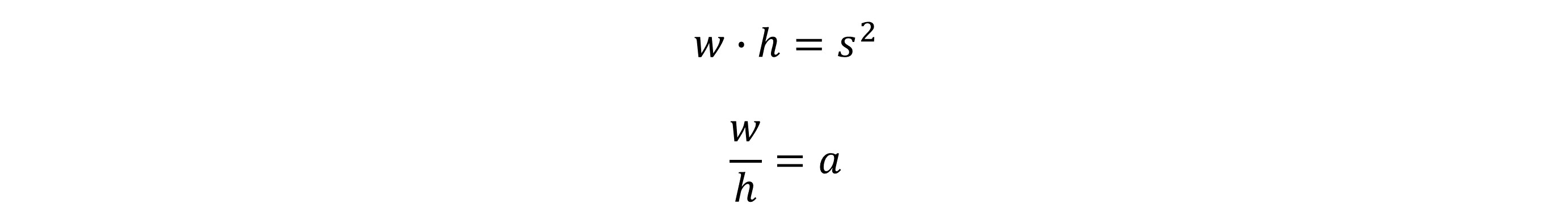
求解w和h可得: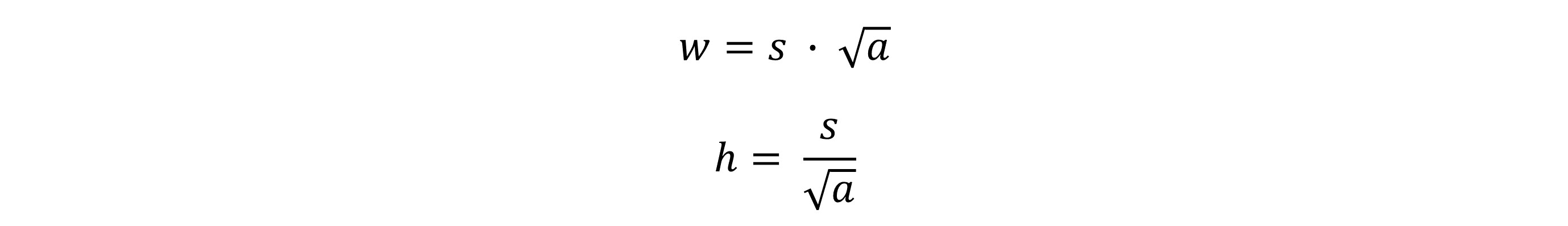
然后以每个feature map上的每个点的中心点为中心,就可以生成一系列不同scale和aspect ratio的prior box。对应代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54def create_prior_boxes():
"""
Create the 8732 prior (default) boxes for the SSD300, as defined in the paper.
:return: prior boxes in center-size coordinates, a tensor of dimensions (8732, 4)
"""
fmap_dims = {'conv4_3': 38,
'conv7': 19,
'conv8_2': 10,
'conv9_2': 5,
'conv10_2': 3,
'conv11_2': 1}
obj_scales = {'conv4_3': 0.1,
'conv7': 0.2,
'conv8_2': 0.375,
'conv9_2': 0.55,
'conv10_2': 0.725,
'conv11_2': 0.9}
aspect_ratios = {'conv4_3': [1., 2., 0.5],
'conv7': [1., 2., 3., 0.5, .333],
'conv8_2': [1., 2., 3., 0.5, .333],
'conv9_2': [1., 2., 3., 0.5, .333],
'conv10_2': [1., 2., 0.5],
'conv11_2': [1., 2., 0.5]}
fmaps = list(fmap_dims.keys())
prior_boxes = []
for k, fmap in enumerate(fmaps):
for i in range(fmap_dims[fmap]):
for j in range(fmap_dims[fmap]):
cx = (j + 0.5) / fmap_dims[fmap]
cy = (i + 0.5) / fmap_dims[fmap]
for ratio in aspect_ratios[fmap]:
prior_boxes.append([cx, cy, obj_scales[fmap] * sqrt(ratio), obj_scales[fmap] / sqrt(ratio)])
# For an aspect ratio of 1, use an additional prior whose scale is the geometric mean of the
# scale of the current feature map and the scale of the next feature map
if ratio == 1.:
try:
additional_scale = sqrt(obj_scales[fmap] * obj_scales[fmaps[k + 1]])
# For the last feature map, there is no "next" feature map
except IndexError:
additional_scale = 1.
prior_boxes.append([cx, cy, additional_scale, additional_scale])
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # (8732, 4)
prior_boxes.clamp_(0, 1) # (8732, 4)
return prior_boxes
Prediction convolutions
前面提及我们使用回归预测来找到目标的bounding box,当然,priors并不能表示我们最终的预测boxes。不过可以priors作为回归的起始框,然后找出需要调整多少才能获得更精确的边界框预测。而我们的目标就是预测这个偏差offsets,如下图示:
通过预测这四个偏差(g_c_x, g_c_y, g_w, g_h)来回归出bounding box的坐标位置。除了预测offsets之外,我们还需要输出对应目标是哪一类的分数scores。以conv9_2为例,对应输出为: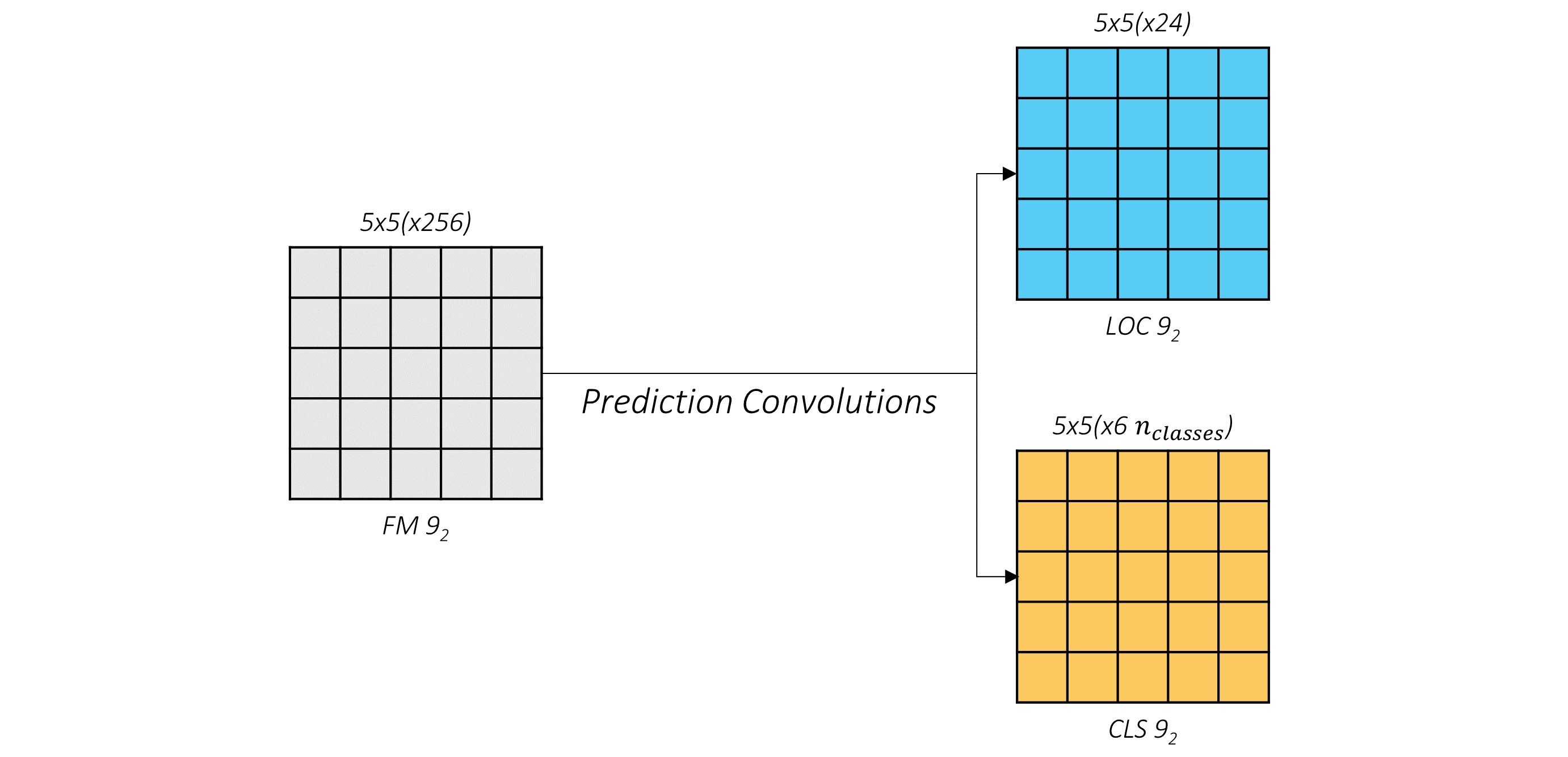
对应6个不同尺度feature map上的输出同样也输出对应的offset和scores,具体代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132class PredictionConvolutions(nn.Module):
"""
Convolutions to predict class scores and bounding boxes using lower and higher-level feature maps.
The bounding boxes (locations) are predicted as encoded offsets w.r.t each of the 8732 prior (default) boxes.
See 'cxcy_to_gcxgcy' in utils.py for the encoding definition.
The class scores represent the scores of each object class in each of the 8732 bounding boxes located.
A high score for 'background' = no object.
"""
def __init__(self, n_classes):
"""
:param n_classes: number of different types of objects
"""
super(PredictionConvolutions, self).__init__()
self.n_classes = n_classes
# Number of prior-boxes we are considering per position in each feature map
n_boxes = {'conv4_3': 4,
'conv7': 6,
'conv8_2': 6,
'conv9_2': 6,
'conv10_2': 4,
'conv11_2': 4}
# 4 prior-boxes implies we use 4 different aspect ratios, etc.
# Localization prediction convolutions (predict offsets w.r.t prior-boxes)
self.loc_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * 4, kernel_size=3, padding=1)
self.loc_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * 4, kernel_size=3, padding=1)
self.loc_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * 4, kernel_size=3, padding=1)
self.loc_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * 4, kernel_size=3, padding=1)
self.loc_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * 4, kernel_size=3, padding=1)
self.loc_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * 4, kernel_size=3, padding=1)
# Class prediction convolutions (predict classes in localization boxes)
self.cl_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * n_classes, kernel_size=3, padding=1)
self.cl_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * n_classes, kernel_size=3, padding=1)
self.cl_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * n_classes, kernel_size=3, padding=1)
self.cl_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * n_classes, kernel_size=3, padding=1)
# Initialize convolutions' parameters
self.init_conv2d()
def init_conv2d(self):
"""
Initialize convolution parameters.
"""
for c in self.children():
if isinstance(c, nn.Conv2d):
nn.init.xavier_uniform_(c.weight)
nn.init.constant_(c.bias, 0.)
def forward(self, conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats):
"""
Forward propagation.
:param conv4_3_feats: conv4_3 feature map, a tensor of dimensions (N, 512, 38, 38)
:param conv7_feats: conv7 feature map, a tensor of dimensions (N, 1024, 19, 19)
:param conv8_2_feats: conv8_2 feature map, a tensor of dimensions (N, 512, 10, 10)
:param conv9_2_feats: conv9_2 feature map, a tensor of dimensions (N, 256, 5, 5)
:param conv10_2_feats: conv10_2 feature map, a tensor of dimensions (N, 256, 3, 3)
:param conv11_2_feats: conv11_2 feature map, a tensor of dimensions (N, 256, 1, 1)
:return: 8732 locations and class scores (i.e. w.r.t each prior box) for each image
"""
batch_size = conv4_3_feats.size(0)
# Predict localization boxes' bounds (as offsets w.r.t prior-boxes)
l_conv4_3 = self.loc_conv4_3(conv4_3_feats) # (N, 16, 38, 38)
l_conv4_3 = l_conv4_3.permute(0, 2, 3,
1).contiguous() # (N, 38, 38, 16), to match prior-box order (after .view())
# (.contiguous() ensures it is stored in a contiguous chunk of memory, needed for .view() below)
l_conv4_3 = l_conv4_3.view(batch_size, -1, 4) # (N, 5776, 4), there are a total 5776 boxes on this feature map
l_conv7 = self.loc_conv7(conv7_feats) # (N, 24, 19, 19)
l_conv7 = l_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 24)
l_conv7 = l_conv7.view(batch_size, -1, 4) # (N, 2166, 4), there are a total 2116 boxes on this feature map
l_conv8_2 = self.loc_conv8_2(conv8_2_feats) # (N, 24, 10, 10)
l_conv8_2 = l_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 24)
l_conv8_2 = l_conv8_2.view(batch_size, -1, 4) # (N, 600, 4)
l_conv9_2 = self.loc_conv9_2(conv9_2_feats) # (N, 24, 5, 5)
l_conv9_2 = l_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 24)
l_conv9_2 = l_conv9_2.view(batch_size, -1, 4) # (N, 150, 4)
l_conv10_2 = self.loc_conv10_2(conv10_2_feats) # (N, 16, 3, 3)
l_conv10_2 = l_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 16)
l_conv10_2 = l_conv10_2.view(batch_size, -1, 4) # (N, 36, 4)
l_conv11_2 = self.loc_conv11_2(conv11_2_feats) # (N, 16, 1, 1)
l_conv11_2 = l_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 16)
l_conv11_2 = l_conv11_2.view(batch_size, -1, 4) # (N, 4, 4)
# Predict classes in localization boxes
c_conv4_3 = self.cl_conv4_3(conv4_3_feats) # (N, 4 * n_classes, 38, 38)
c_conv4_3 = c_conv4_3.permute(0, 2, 3,
1).contiguous() # (N, 38, 38, 4 * n_classes), to match prior-box order (after .view())
c_conv4_3 = c_conv4_3.view(batch_size, -1,
self.n_classes) # (N, 5776, n_classes), there are a total 5776 boxes on this feature map
c_conv7 = self.cl_conv7(conv7_feats) # (N, 6 * n_classes, 19, 19)
c_conv7 = c_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 6 * n_classes)
c_conv7 = c_conv7.view(batch_size, -1,
self.n_classes) # (N, 2166, n_classes), there are a total 2116 boxes on this feature map
c_conv8_2 = self.cl_conv8_2(conv8_2_feats) # (N, 6 * n_classes, 10, 10)
c_conv8_2 = c_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 6 * n_classes)
c_conv8_2 = c_conv8_2.view(batch_size, -1, self.n_classes) # (N, 600, n_classes)
c_conv9_2 = self.cl_conv9_2(conv9_2_feats) # (N, 6 * n_classes, 5, 5)
c_conv9_2 = c_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 6 * n_classes)
c_conv9_2 = c_conv9_2.view(batch_size, -1, self.n_classes) # (N, 150, n_classes)
c_conv10_2 = self.cl_conv10_2(conv10_2_feats) # (N, 4 * n_classes, 3, 3)
c_conv10_2 = c_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 4 * n_classes)
c_conv10_2 = c_conv10_2.view(batch_size, -1, self.n_classes) # (N, 36, n_classes)
c_conv11_2 = self.cl_conv11_2(conv11_2_feats) # (N, 4 * n_classes, 1, 1)
c_conv11_2 = c_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 4 * n_classes)
c_conv11_2 = c_conv11_2.view(batch_size, -1, self.n_classes) # (N, 4, n_classes)
# A total of 8732 boxes
# Concatenate in this specific order (i.e. must match the order of the prior-boxes)
locs = torch.cat([l_conv4_3, l_conv7, l_conv8_2, l_conv9_2, l_conv10_2, l_conv11_2], dim=1) # (N, 8732, 4)
classes_scores = torch.cat([c_conv4_3, c_conv7, c_conv8_2, c_conv9_2, c_conv10_2, c_conv11_2],
dim=1) # (N, 8732, n_classes)
return locs, classes_scores
Multibox loss
与常见的 Object Detection模型的目标函数相同,SSD算法的目标函数分为两部分:计算相应的prior box与目标类别的confidence loss以及相应的位置回归Localization loss。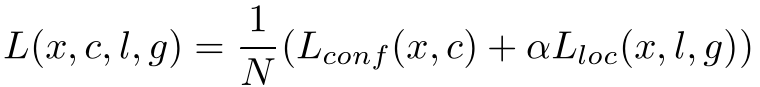
loss的计算过程如下:
Localization loss
- 计算8732个prior box与groud truth的IOU重叠值,保留重合度大于0.5的所有priors,对应的prior也成为positive prior;在论文中换了个名词Jaccard overlaps,其实和IOU是一个意思;
- 由于网络输出的是相对于priors的预测偏差(g_c_x, g_c_y, g_w, g_h),因此我们需要将positive prior转换为绝对坐标位置,然后与groud truth计算smooth l1 loss;
- smooth l1 loss损失计算如下:

Confidence loss
在计算Localization loss中,只计算了positive prior的损失,没有计算negative prior的损失是因为标签中只有positive prior对应的gt。而在计算Confidence loss的不一样,每一次预测,不管正样本和是负样本都存在一个与之对应的标签。注意,这里的正负样本都是基于positive prior,iou>0.5的prior box,正确分类为目标类别的为正样本,否则为负样本。在SSD中使用了hard negative mining。这是因为在positive prior中,分类正样本和负样本存在大量不平衡问题,因此使用hard negative mining来缓解这个问题。在这里,正样本与负样本的数量比例为1:3,负样本选择分类置信度靠前的。Confidence loss使用的交叉熵损失函数,如下: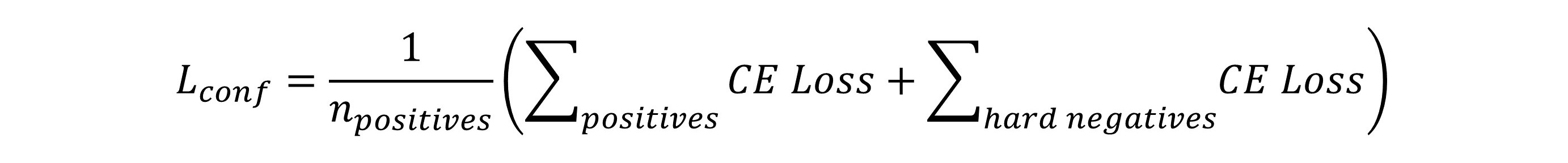
在SSD中,最后整个算法模型的损失函数为: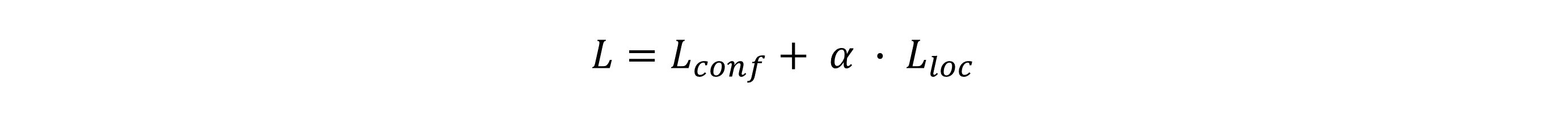
具体代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120class MultiBoxLoss(nn.Module):
"""
The MultiBox loss, a loss function for object detection.
This is a combination of:
(1) a localization loss for the predicted locations of the boxes, and
(2) a confidence loss for the predicted class scores.
"""
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.):
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy #priors_cxcy即上面create_prior_boxes()生成的8732 priorbox
print(self.priors_cxcy[0])
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = nn.L1Loss()
self.cross_entropy = nn.CrossEntropyLoss(reduce=False)
def forward(self, predicted_locs, predicted_scores, boxes, labels):
"""
Forward propagation.
:param predicted_locs: predicted locations/boxes w.r.t the 8732 prior boxes, a tensor of dimensions (N, 8732, 4)
:param predicted_scores: class scores for each of the encoded locations/boxes, a tensor of dimensions (N, 8732, n_classes)
:param boxes: true object bounding boxes in boundary coordinates, a list of N tensors
:param labels: true object labels, a list of N tensors
:return: multibox loss, a scalar
"""
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
print (self.priors_xy[0:2])
n_classes = predicted_scores.size(2)
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
true_locs = torch.zeros((batch_size, n_priors, 4), dtype=torch.float).to(device) # (N, 8732, 4)
true_classes = torch.zeros((batch_size, n_priors), dtype=torch.long).to(device) # (N, 8732)
# For each image
for i in range(batch_size):
n_objects = boxes[i].size(0)
overlap = find_jaccard_overlap(boxes[i],
self.priors_xy) # (n_objects, 8732)
# For each prior, find the object that has the maximum overlap
overlap_for_each_prior, object_for_each_prior = overlap.max(dim=0) # (8732)
# We don't want a situation where an object is not represented in our positive (non-background) priors -
# 1. An object might not be the best object for all priors, and is therefore not in object_for_each_prior.
# 2. All priors with the object may be assigned as background based on the threshold (0.5).
# To remedy this -
# First, find the prior that has the maximum overlap for each object.
_, prior_for_each_object = overlap.max(dim=1) # (N_o)
# Then, assign each object to the corresponding maximum-overlap-prior. (This fixes 1.)
object_for_each_prior[prior_for_each_object] = torch.LongTensor(range(n_objects)).to(device)
# To ensure these priors qualify, artificially give them an overlap of greater than 0.5. (This fixes 2.)
overlap_for_each_prior[prior_for_each_object] = 1.
# Labels for each prior
label_for_each_prior = labels[i][object_for_each_prior] # (8732)
# Set priors whose overlaps with objects are less than the threshold to be background (no object)
label_for_each_prior[overlap_for_each_prior < self.threshold] = 0 # (8732)
# Store
true_classes[i] = label_for_each_prior
# Encode center-size object coordinates into the form we regressed predicted boxes to
true_locs[i] = cxcy_to_gcxgcy(xy_to_cxcy(boxes[i][object_for_each_prior]), self.priors_cxcy) # (8732, 4)
# Identify priors that are positive (object/non-background)
positive_priors = true_classes != 0 # (N, 8732)
# LOCALIZATION LOSS
# Localization loss is computed only over positive (non-background) priors
loc_loss = self.smooth_l1(predicted_locs[positive_priors], true_locs[positive_priors]) # (), scalar
# Note: indexing with a torch.uint8 (byte) tensor flattens the tensor when indexing is across multiple dimensions (N & 8732)
# So, if predicted_locs has the shape (N, 8732, 4), predicted_locs[positive_priors] will have (total positives, 4)
# CONFIDENCE LOSS
# Confidence loss is computed over positive priors and the most difficult (hardest) negative priors in each image
# That is, FOR EACH IMAGE,
# we will take the hardest (neg_pos_ratio * n_positives) negative priors, i.e where there is maximum loss
# This is called Hard Negative Mining - it concentrates on hardest negatives in each image, and also minimizes pos/neg imbalance
# Number of positive and hard-negative priors per image
n_positives = positive_priors.sum(dim=1) # (N)
n_hard_negatives = self.neg_pos_ratio * n_positives # (N)
# First, find the loss for all priors
conf_loss_all = self.cross_entropy(predicted_scores.view(-1, n_classes), true_classes.view(-1)) # (N * 8732)
conf_loss_all = conf_loss_all.view(batch_size, n_priors) # (N, 8732)
# We already know which priors are positive
conf_loss_pos = conf_loss_all[positive_priors] # (sum(n_positives))
# Next, find which priors are hard-negative
# To do this, sort ONLY negative priors in each image in order of decreasing loss and take top n_hard_negatives
conf_loss_neg = conf_loss_all.clone() # (N, 8732)
conf_loss_neg[positive_priors] = 0. # (N, 8732), positive priors are ignored (never in top n_hard_negatives)
conf_loss_neg, _ = conf_loss_neg.sort(dim=1, descending=True) # (N, 8732), sorted by decreasing hardness
hardness_ranks = torch.LongTensor(range(n_priors)).unsqueeze(0).expand_as(conf_loss_neg).to(device) # (N, 8732)
hard_negatives = hardness_ranks < n_hard_negatives.unsqueeze(1) # (N, 8732)
conf_loss_hard_neg = conf_loss_neg[hard_negatives] # (sum(n_hard_negatives))
# As in the paper, averaged over positive priors only, although computed over both positive and hard-negative priors
conf_loss = (conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.sum().float() # (), scalar
# TOTAL LOSS
return conf_loss + self.alpha * loc_loss
Processing predictions
对模型进行训练后,我们可以将其应用于图像目标检测。然而,模型预测输出的是包含8732个priors的偏移量和类别分数。因此需要对这些进行后处理,以获得最终的目标检测的边界框。大致过程如下:
(1)在获得了8732个priors的预测偏移量(g_c_x, g_c_y, g_w, g_h)之后,通过如下公式进行逆运算转换成绝对坐标:
(2)通过NMS(非最大值抑制)过滤掉背景和得分不是很高的框(这个是为了避免重复预测),得到最终的预测。
具体代码实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104def detect_objects(self, predicted_locs, predicted_scores, min_score, max_overlap, top_k):
"""
Decipher the 8732 locations and class scores (output of ths SSD300) to detect objects.
For each class, perform Non-Maximum Suppression (NMS) on boxes that are above a minimum threshold.
:param predicted_locs: predicted locations/boxes w.r.t the 8732 prior boxes, a tensor of dimensions (N, 8732, 4)
:param predicted_scores: class scores for each of the encoded locations/boxes, a tensor of dimensions (N, 8732, n_classes)
:param min_score: minimum threshold for a box to be considered a match for a certain class
:param max_overlap: maximum overlap two boxes can have so that the one with the lower score is not suppressed via NMS
:param top_k: if there are a lot of resulting detection across all classes, keep only the top 'k'
:return: detections (boxes, labels, and scores), lists of length batch_size
"""
batch_size = predicted_locs.size(0)
n_priors = self.priors_cxcy.size(0)
predicted_scores = F.softmax(predicted_scores, dim=2) # (N, 8732, n_classes)
# Lists to store final predicted boxes, labels, and scores for all images
all_images_boxes = list()
all_images_labels = list()
all_images_scores = list()
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
for i in range(batch_size):
# Decode object coordinates from the form we regressed predicted boxes to
decoded_locs = cxcy_to_xy(
gcxgcy_to_cxcy(predicted_locs[i], self.priors_cxcy)) # (8732, 4), these are fractional pt. coordinates
# Lists to store boxes and scores for this image
image_boxes = list()
image_labels = list()
image_scores = list()
max_scores, best_label = predicted_scores[i].max(dim=1) # (8732)
# Check for each class
for c in range(1, self.n_classes):
# Keep only predicted boxes and scores where scores for this class are above the minimum score
class_scores = predicted_scores[i][:, c] # (8732)
score_above_min_score = class_scores > min_score # torch.uint8 (byte) tensor, for indexing
n_above_min_score = score_above_min_score.sum().item()
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score] # (n_qualified), n_min_score <= 8732
class_decoded_locs = decoded_locs[score_above_min_score] # (n_qualified, 4)
# Sort predicted boxes and scores by scores
class_scores, sort_ind = class_scores.sort(dim=0, descending=True) # (n_qualified), (n_min_score)
class_decoded_locs = class_decoded_locs[sort_ind] # (n_min_score, 4)
# Find the overlap between predicted boxes
overlap = find_jaccard_overlap(class_decoded_locs, class_decoded_locs) # (n_qualified, n_min_score)
# Non-Maximum Suppression (NMS)
# A torch.uint8 (byte) tensor to keep track of which predicted boxes to suppress
# 1 implies suppress, 0 implies don't suppress
suppress = torch.zeros((n_above_min_score), dtype=torch.uint8).to(device) # (n_qualified)
# Consider each box in order of decreasing scores
for box in range(class_decoded_locs.size(0)):
# If this box is already marked for suppression
if suppress[box] == 1:
continue
# Suppress boxes whose overlaps (with this box) are greater than maximum overlap
# Find such boxes and update suppress indices
suppress = torch.max(suppress, overlap[box] > max_overlap)
# The max operation retains previously suppressed boxes, like an 'OR' operation
# Don't suppress this box, even though it has an overlap of 1 with itself
suppress[box] = 0
# Store only unsuppressed boxes for this class
image_boxes.append(class_decoded_locs[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
# If no object in any class is found, store a placeholder for 'background'
if len(image_boxes) == 0:
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.LongTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
# Concatenate into single tensors
image_boxes = torch.cat(image_boxes, dim=0) # (n_objects, 4)
image_labels = torch.cat(image_labels, dim=0) # (n_objects)
image_scores = torch.cat(image_scores, dim=0) # (n_objects)
n_objects = image_scores.size(0)
# Keep only the top k objects
if n_objects > top_k:
image_scores, sort_ind = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_ind][:top_k] # (top_k, 4)
image_labels = image_labels[sort_ind][:top_k] # (top_k)
# Append to lists that store predicted boxes and scores for all images
all_images_boxes.append(image_boxes)
all_images_labels.append(image_labels)
all_images_scores.append(image_scores)
return all_images_boxes, all_images_labels, all_images_scores # lists of length batch_size
Dataset
在SSD中作者使用VOC2007和VOC2012数据集进行实验验证,两个数据集是互斥,不相容的。在SSD论文中针对 VOC2007和VOC2012 的具体用法有以下几种:
- 07: VOC2007 trainval ,做训练数据;
- 07+12: VOC2007 trainval + VOC200712 trainval,两者组合作为训练数据;
- 07++12: VOC2007 trainval + VOC200712 trainval + VOC2007 test, 三者组合作为训练数据;
此外,还有先在coco进行预训练,然后再VOC上进行finetune的用法:
- 07+12+coco: VOC2007 trainval + VOC200712 trainval + coco trainval135k, 表示先在coco trainval135k上训练,然后使用07+12进行finetune;
- 07++12+coco: VOC2007 trainval + VOC2007 test + VOC200712 trainval + coco trainval135k, 表示先在coco trainval135k上训练,然后使用07++12进行finetune;
code
SSD300实现的完整代码:https://github.com/nicehuster/ssd.pytorch